k-means 介紹
k-means 又稱 c-means Clustering,是一種分群演算法,k 表示群集的數量,演算法如下
- 給定一資料集 S,選擇 k 個點當群集中心,也稱為群心。
- 計算每一資料與各群心距離,資料歸類在與之最短距離的群心那群。
- 歸類好的資料再算出一個新的群心,通常是使用平均值。
- 比較新的群心與舊的群心位置是否接近或者固定。
- 重複 2 ~ 4 直到 4 成立,則分群完畢。
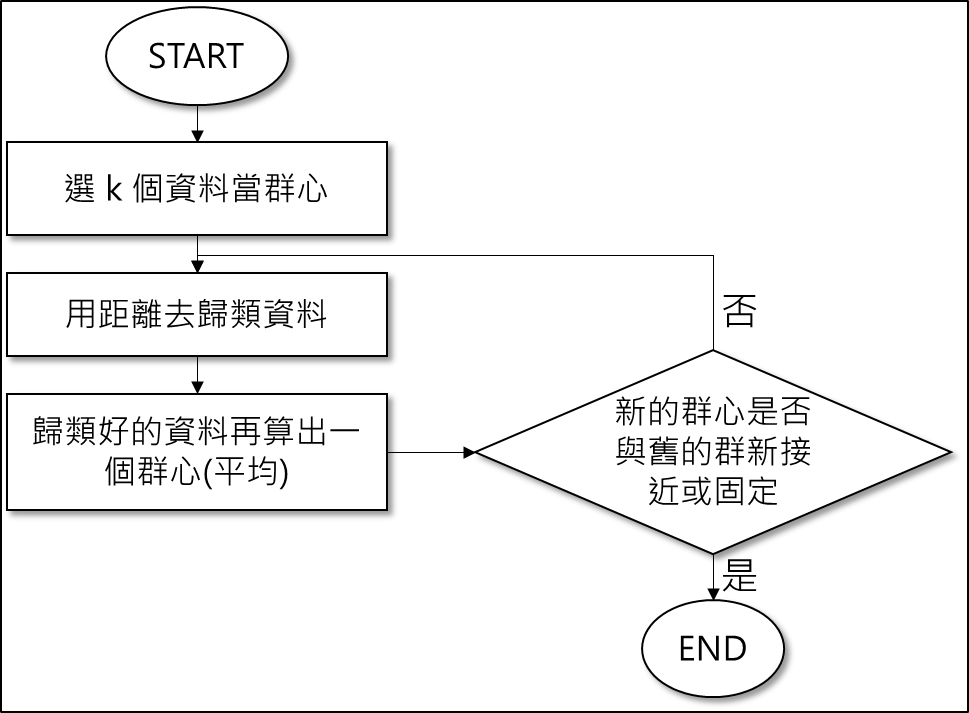 k-means 流程圖
k-means 流程圖
Pseudo code
Pseudo code 如下,先定義參數
- Input : 群數
k, 群心 Centers of clusters(kC) - Output:分群結果
team - Subroutine:算距離
distFunc, 算新的群心re_center, 分群clustering
1 | main k_means(Database, k, kC, distFunc, re_center, k_clustering) |
MATLAB code
MATLAB code
1 | function [team kx ky]= k_means(x, y, kx, ky, seed_num) |

