前言
一著名的強化學習演算法為 Q Learning,可以這樣比喻它學習的方式:小孩對世界充滿了好奇並探索時,會觀察父母的表情來判斷當下的行為是好或壞,或者做什麼事會得到糖果或被懲罰,再藉由這些過去的經驗得到更多獎勵。此篇文章藉由 Q Learning 的想法來實現 AI 自走迷宮,透過簡短的程式讓 Q Learning 的學習步驟具象化,非常適合已先自行閱讀 Q Learning 演算法相關文章但頭腦還處於混沌、難以想像 Q Learning 實際運作的讀者。
成果
環境
- Python 3.9.5
- pip 21.3.1
- numpy 1.21.4
建立迷宮地圖
二維迷宮地圖使用二維陣列來記錄最容易,並定義數值的涵意:-1 為起始點、0 為可行走的路、1 為牆、 2 為終點
1 | # -1 is origin, 0 is road, 1 is wall, 2 is goal |
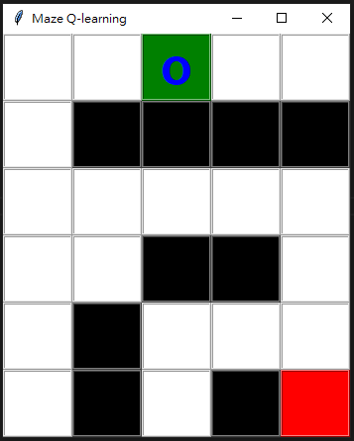 二維陣列實際對應的迷宮
二維陣列實際對應的迷宮
建立遊戲環境 (Environment)
除迷宮地圖外,還需要一個環境來對我們做的每個動作給予回饋,就如同小孩的動作與父母的回饋 (之於動作與環境回饋)。建立環境前,需先定義狀態 (State)、動作 (Action) 與獎懲機制 (Reward)。
定義狀態
每一個時間點都會有一個可以描述的狀態,以二維迷宮來說,這個狀態可以定義為 Player 所在的位置 state = (row, column),若 state 為 (1, 2) 表示 Player 所處狀態為 row = 1 且 column = 2。
定義動作
對迷宮來說,只會有四個動作 up、down、left、right 分別代表上、下、左、右
1 | # Determine the result of an action in this state. |
up:往上移動,即row = row - 1。down:往下移動,即row = row + 1。left:往左移動,即column = column - 1。right:往右移動,即column = column + 1。try ... except:根據現在的狀態 (state) 計算出下一個狀態 (nextState)。
定義獎懲機制
環境執行完對應的動作並取得下一個狀態後,即可針對這些資訊來計算對應的獎懲分數
1 | # Execute action. |
No move: 碰到牆或是邊界,即執行完動作還停在原地,回饋-10分。Forward: 可以移動,但沒有到達終點,回饋-1分。Goal:到達終點,回饋100分。
遊戲環境的使用方法
實作出環境後,我們便只需跟環境說:「Hi,我現在的狀態是 (1, 2),我要做的動作是 up,請問得到多少回饋分數 (reward)?下個狀態會是什麼 (nextState)?遊戲結束了嗎 (result)?」
1 | # Give the action to the Environment to execute |
建立代理人 (Agent)
要真的實現 AI 玩遊戲之前,需要建立一個代理人,讓代理人代替真人去玩遊戲,換句話說:就是讓 AI 自己 (Agent) 與遊戲環境 (Environment) 去互動。而我們的 Q Learning 就是實作在代理人這端,讓代理人可以根據 Q Table 與當前狀態,來決定下一個要執行的動作是什麼,在過程中不停的透過決策與獎勵來更新手上的 Q Table,最後精通遊戲的玩法,即為 Q Learning 的精髓所在。
建立 Q Table
Q Table 是一個狀態 (state) 與動作 (action) 的對應表,紀錄下每個決策預期可護得的獎勵,我們的狀態是 (row, column) 而動作是 up、down、left、right,因此可以將 Q Table 格式定義如下
1 | # 先定義變量 |
Q Table 格式不是只能使用陣列的型式表示,只要資料結構能滿足記錄 state 和 action 的對應,都是很好的!
因為剛開始 AI 對環境還不了解,每個狀態、每個動作對 AI 來說都是一樣的,因此將 Q Table 中所有的分數初始化為 0
1 | def initQTable(self): |
選擇動作
Q Table 代表以往決策的經驗,因此 AI 可以使用當前的狀態去查表得知應該要執行什麼動作,才有可能獲得較高的分數
1 | def getAction(self, eGreddy=0.8): |
eGreddy:為一機率值,若random.random() > eGreddy成立則不參考 Q Table,隨機選一個動作做為決策,這項機制是防止代理人進入有可能出現的無窮迴圈。
更新 Q Table
這裡即為 Q Learning 演算法的核心,更新 Q Table
1 | def updateQTable(self, action, nextState, reward, lr=0.7, gamma=0.9): |
Qsa對應公式為 $Q(s, a)$lr對應公式為 $\alpha$reward對應公式為 $r$gamma對應公式為 $\gamma$getNextMaxQ(nextState)對應公式為 $max_{a'}Q(s', a')$
代理人與遊戲環境互動
使用 while True 讓代理人待在玩遊戲的迴圈內,直至到達終點 if result,詳細說明可參考程式內註解
1 | initState = (np.where(maze==-1)[0][0], np.where(maze==-1)[1][0]) |
結語
強化學習能從無任何資訊去學出一套規則,就像人從小就會觀察這個世界給我們的回饋,不論這樣的回饋是來自父母、朋友、同學、師長、甚至是陌生人,都會對我們人生中的決策產生一定的影響。每個人手裡都握有一個 Q Table,也都正在努力更新、優化這張表、盡可能地嘗試各種不一樣的機會,都是希望能透過現在的經驗,引導未來的自己邁向心中的那個理想。

