前言
至五月以來,疫情爆發升級成三級警戒,戴口罩已成為日常生活不可或缺的一部分。然而,還是時常在新聞上看到不配合戴口罩的名眾,想成為防疫破口,為了監視這些人的行為還需要額外人力去支援。剛好,在課堂上學到如何用 CNN 網路模型來做圖片辨識,因此以時事為主題,學習為主旨來做這份期末報告。
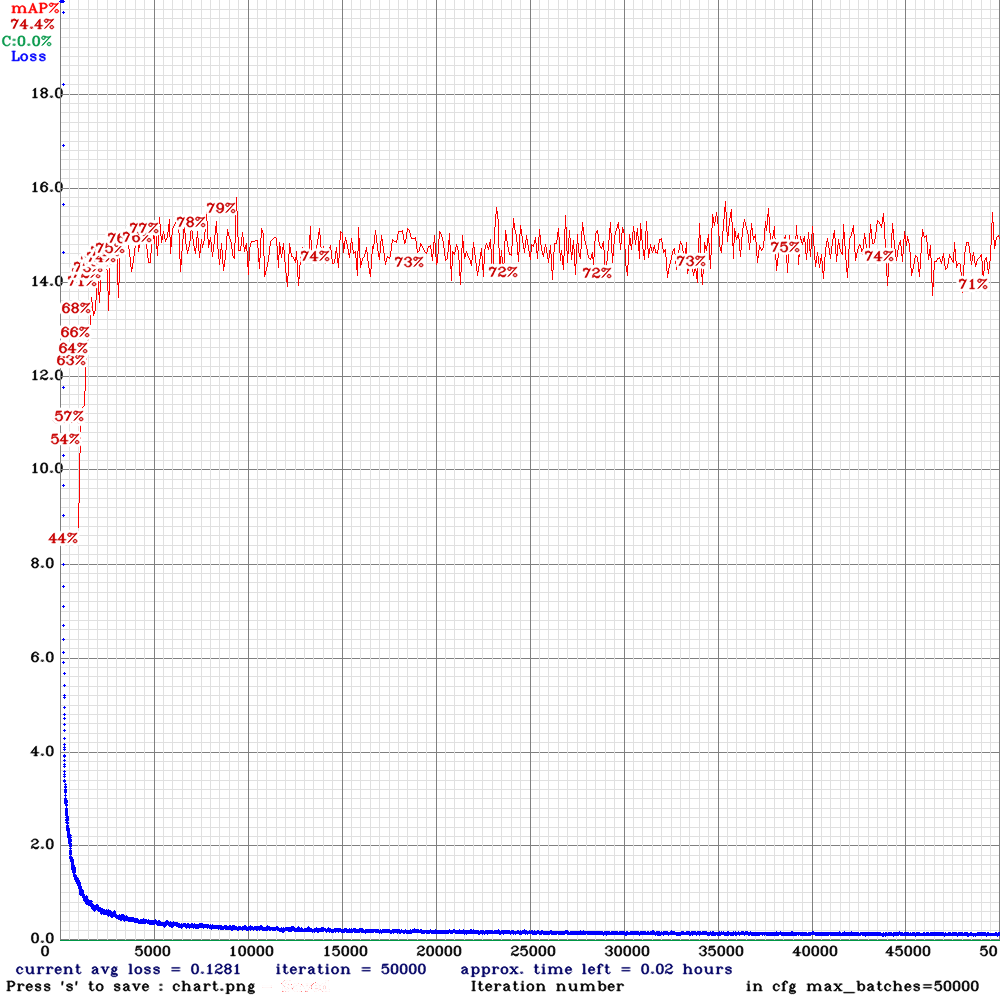
我們從國際上著名的數據庫 Kaggle 平台取得想要的資料集 Face Mask Detection,裡面有853張照片、三種物件,分別為戴口罩的人頭、沒戴口罩的人頭、口罩戴的不完全的人頭。並使用 YOLOv4 (You Only Look Once) 物件辨識演算法來偵測戴口罩的人。最後的訓練成效 mAP 為 79%,同時為了能公開讓大家一同使用,將結果透過 Line 平台的 Line Bot 系統整合 YOLOv4 訓練結果,只需直接上傳圖片就可以即時得到回饋。
此篇文章使用方法
開發環境為
Ubuntu 16.04 LTS桌面版本,並且每個路徑都以絕對路徑來呈現,盡量使所有路徑透明化,避免讀者混淆。因此若要照著本文提供的程式運行的話,路徑中的user需改為登入環境的帳號名稱。作者不講清楚目錄結構常常是讀者的一個痛點,因此本文在每個段落都會顯示出目錄結構給讀者參考,建議讀者經常比對自己的目錄結構是否與本文相同,不相同的話容易出現意想不到的錯誤。
Kaggle
Kaggle 是什麼?
Kaggle 是一個數據建模和數據分析競賽平台。企業和研究者可在其上發布數據,統計學者和數據可在其上進行競賽以產生最好的模型。可以分為
- Competitions競賽
Kaggle 的比賽類型按照獎勵內容可以分成3種- 提供獎金的 Featured 類。
- 提供實習、面試機會的 Recruitment 類。
- 純粹作為練手的 Playground 類。
- Datasets 數據集
利用 Kaggle 的數據集,通過簡單的Dig in → Build → Connect的步驟,就可以自己挖掘、分析公共數據集的內容。Dig in:直接在 Kaggle 上使用其提供的交互式工具來進行數據分析,支持 Python、Julia、R Markdown、SQLite 等語言,Kaggle 通過相應的 Docker 容器來編譯執行腳本。Build:網頁版工具上進行數據分析處理之後,可以發布自己的數據 insights,使用 Kaggle Kernels 來 coding。Connect:可以很方便的查看其他人公開的 Kaggle Kernels,或者在論壇中諮詢對應數據集的相關問題。
- Kernel 內核
- 以前叫做 Scripts,現在改名叫 Kernels 了。Kernels 提供了數據分析所需的環境、數據集、代碼和輸出樣式(比如 Python Notebook),Kaggle 的目的是要使得 Kernels 成為數據分析的核心,他們想將 Kernels 打造為一個能實現並分享所有數據科學工作的平台,包括與本地工具的結合(Kernels 現在提供的環境庫並沒有辦法做到包羅萬象)、團隊間的私有合作空間等等。
- 之前 Datasets 里面的網頁版工具就是調用了 Kaggle 的 Kernels 平台,其一大好處就在於不需要將數據集下載在電腦,Kernels 中已經預先載入了龐大的數據集和基本的數據處理環境資料庫(甚至都不需要在本地配環境!)。這點很棒,畢竟龐大的數據要下載下來在網絡條件不允許的情況下還是相當耗費時間,在本地配好一系列的數據處理環境也不容易,Kernels 借助 Docker 鏡像解決了這一問題。(類似的數據上雲的方式開始越來越流行)
Kaggle 優點
- 真實的數據:在自己學習數據分析的過程中,很多時候是苦於沒有數據,很多書或課程的數據都是無法參考,數據量小,而真實世界的數據往往都是大量,到處充滿了缺失和不足,實際的數據分析工作中。
- 真實的問題:在 Kaggle 上發布的競賽題目,一般都是企業或政府組織中真實面臨的問題。實際的數據分析工作都是從實際問題出發,選擇解決辦法的時候要考慮到各種因素,沒有絕對的對與錯,都是要根據實際問題,具體問題具體分析。
- 及時的反饋:而在 Kaggle 上,只要提交了算法結果,就可以在 Leader board 上看到自己的排名和成績,你可以不斷改進,如果一次改進可以提高排名。
- 線上的討論:每給 Kaggle 競賽題目都配有一個論壇,參賽者在賽中和賽後可以相互討論,這讓學習不再孤單,可以在討論中吸取別人的想法,也可以為他人提供指導。
YOLO
YOLO 簡介
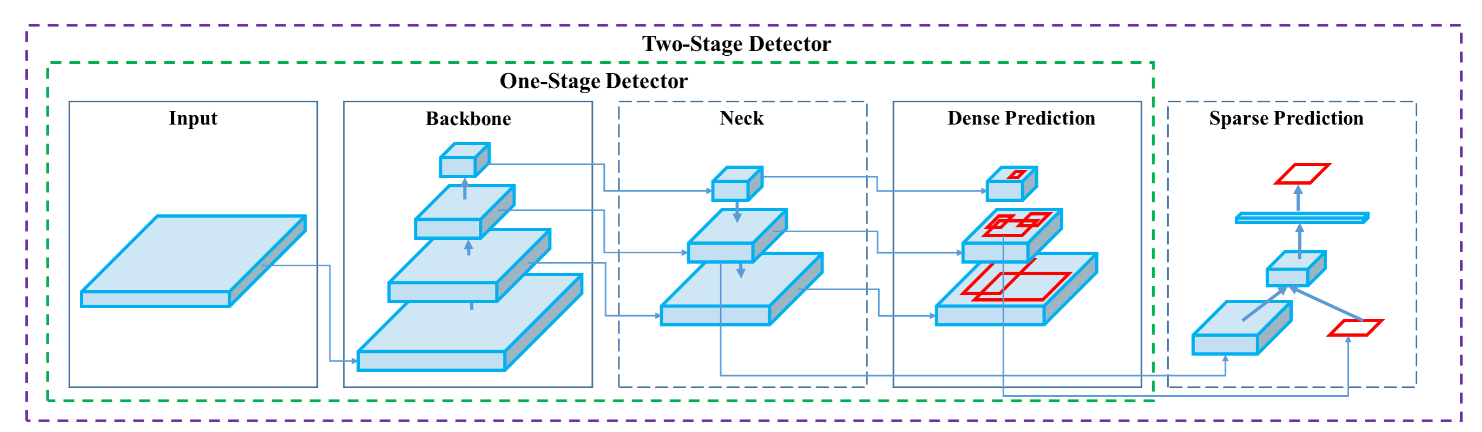
YOLO (You Only Look Once) 是一種影像物件辨識演算法,為 One stage 的物件偵測方法,只需使用一個 CNN 架構就能判斷圖片內的物體位置與類別。相對於此種物件偵測的是 Two stage (例如 R-CNN),該演算法必須先偵測出物件,再對每個物件個別做 CNN 運算判斷物件類別,因此 YOLO 相較可以提升辨識速度。
 One Stage 示意圖
One Stage 示意圖
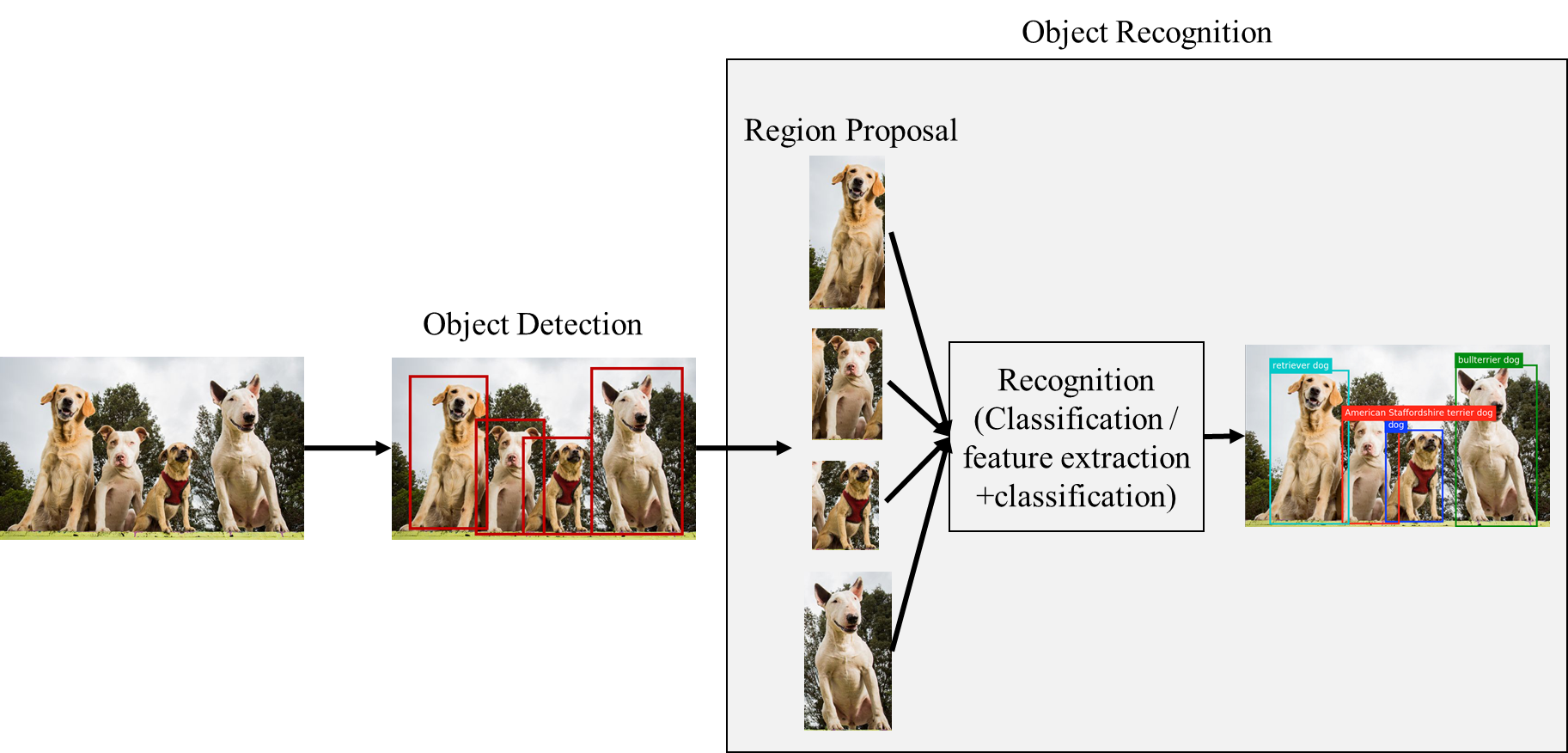 Two Stage 示意圖
Two Stage 示意圖
YOLO 作法就是將輸入的影像切割成 S*S的網格,若物體的中心若在某網格內,則該網格負責檢測該物體。
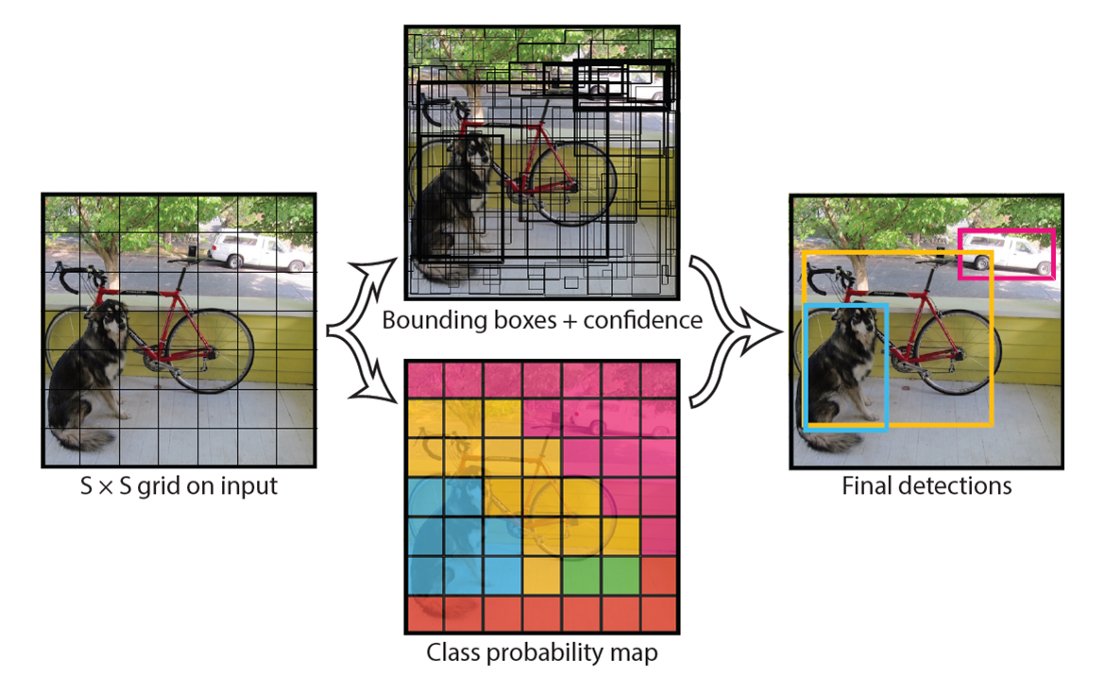 YOLO 運作原理
YOLO 運作原理
在訓練時,每個網格會預測出 B 個 bounding boxes,每個 bounding box 對應 5 個預測結果
- bounding box 的中心點座標$(x,y)$與寬高$(w,h)$
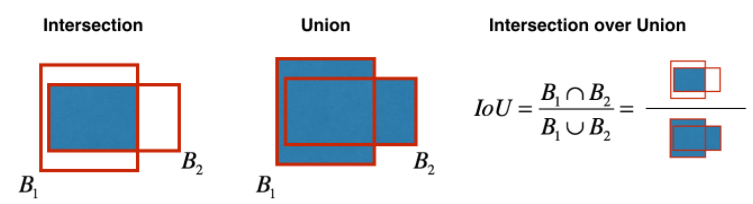
信心評分代表 bounding box 與 Ground Truth 的 IoU 值
 Intersection over Union
Intersection over Union
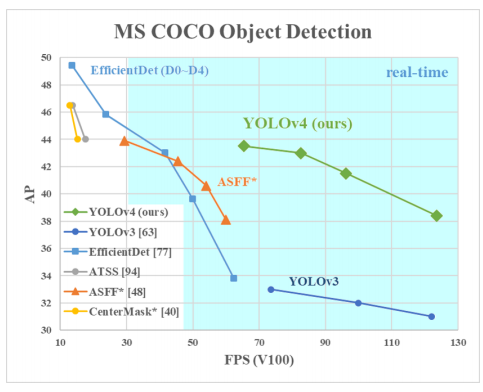
Why YOLOv4
- YOLOv4 在 YOLOv3 各個部分做改進,在同樣的速率(FPS)提升近 12% AP,
YOLOv4 Performance - YOLOv4 貢獻有三[4]
- 此高效有力的物件模型,使用 1080Ti 或 2080Ti 就能進行訓練。
- 驗證最新的 Bag-of-Freebies 與 Bag-of-Specials 方法在物件偵測模型訓練中的影響。
- 微調最新的的方法例如 CBN、PAN、SAM,使其在單 GPU 訓練中更有效率。
- YOLOv4 有共有三名作者,一名為俄羅斯人,另外兩名為台灣中研院研究員,身為台灣人當然要挺自己人研發的模型。
YOLOv4 Authors

YOLOv4 結構[4]
 YOLOv4 Structure
YOLOv4 Structure
Backborn:對 ImageNet 做預訓練。
Neck:在head 與backborn 之間的 layers,通常用來收集不同級的特徵。
Head:預測類別與 bounding box。
YOLOv4 各部分組成如下:
- Backbone: CSPDarknet53 [81]
- Neck: SPP [25], PAN [49]
- Head: YOLOv3 [63]
使用 YOLOv4
資料集處理
選用 Kaggle 的 Face Mask Detection 資料集。
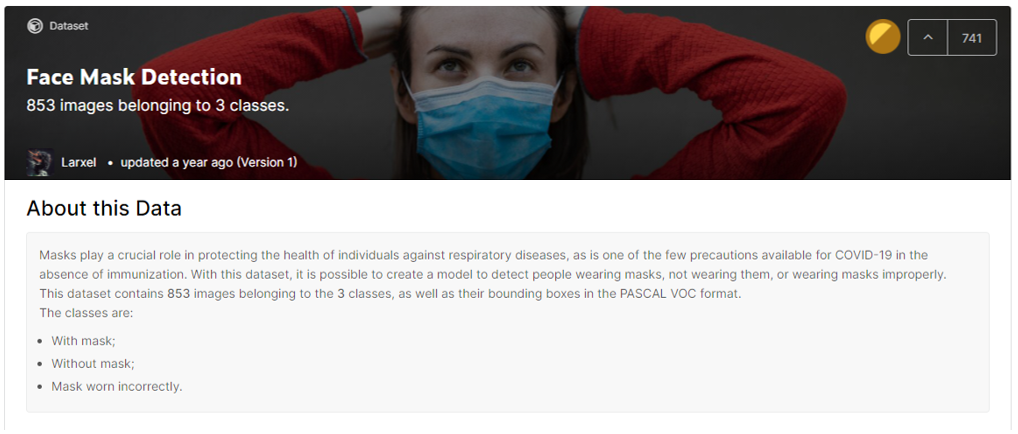 Face Mask Detection Cover
Face Mask Detection Cover
至該網站下載並解壓縮到 kaggle_face_mask 目錄下,目錄結構如下,共有 853 張照片(*.png)/853 標籤檔(*.xml)。
1 | /home/user/kaggle_face_mask |
標籤為 PASCAL VOC 格式
 PASCAL VOC 解讀示意圖
PASCAL VOC 解讀示意圖
轉換 PASCAL VOC 格式為 YOLO 格式
YOLO 的標籤檔為 txt 檔,並與圖檔放在同一名稱放同一目錄下。格式如下,若有多個物件,就記錄多行
1 | classId xCenter yCenter bndBoxW bndBoxH |
以下為換算公式,其中 $w$ 與 $h$ 為圖片本身的寬與長。
以下舉 maksssksksss0.png 為範例
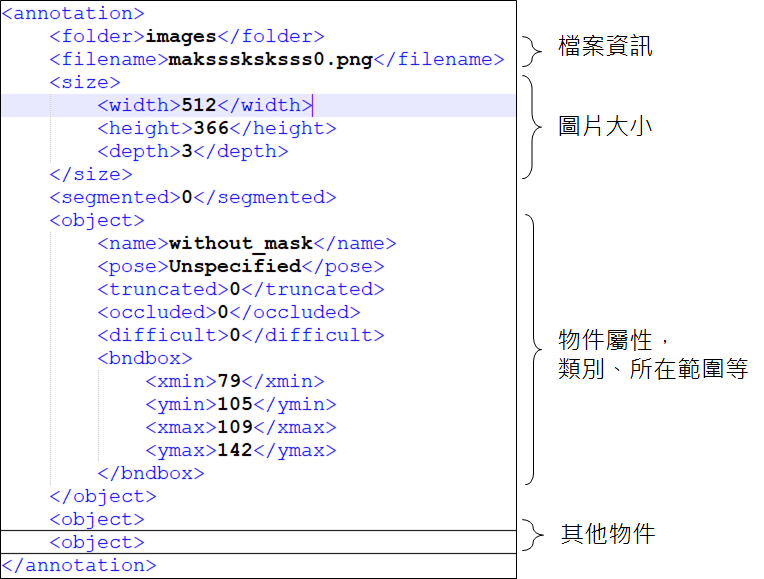 maksssksksss0.png 的 PASCAL VOC 標籤
maksssksksss0.png 的 PASCAL VOC 標籤
將該 VOC 轉為 YOLO 應如下,其中定義 classId=0 為 with_mask、 classId=1 為 without_mask、classId=2 為 mask_weared_incorrect
1 | 1 0.18359375 0.337431693989071 0.05859375 0.10109289617486339 |
透過以下 Python 程式將 VOC 轉為 YOLO
1 | import os, shutil |
現在目錄結構為
1 | /home/user |
分類為 training data 與 validation data
選擇 80% 的資料量為 training data、20% 為 validation data
pie
"Training Data" : 80
"Validation Data" : 20
1 | import os |
執行完上方程式後,會出現兩個檔案,train.txt 與 val.txt ,分別記錄 training data 與 validation data 的路徑
1 | /home/user/yolo_data/maksssksksss166.png |
1 | /home/user/yolo_data/maksssksksss17.png |
現在的目錄結構為
1 | /home/user |
準備訓練所需設定檔
安裝 YOLOv4
先下載原始碼
1 | cd /home/user |
修改 darknet 的 Makefile,
1 | sed -i "s/GPU=0/GPU=1/" /home/user/darknet/Makefile |
編譯 darknet
1 | cd /home/user/darknet |
建立 cfg 目錄
創建目錄,並且移動 train.txt 與 val.txt
1 | mkdir -p /home/user/mask_detection/cfg/weights |
在 cfg 目錄中創建以下兩個檔案,
mask.data
1 | classes = 3 |
mask.names
1 | with_mask |
*.data:記錄類別數量(classes)、train.txt 的位置(train)、val.txt 的位置(valid)、mask.names 檔案位置(names)、weights 輸出的路徑 (backup)。*.names:記錄各類別名稱,第一行名稱對應到classId=0,以此類推。
複製 yolov4-tiny-custom.cfg 到 cfg 目錄下
1 | cp /home/user/darknet/cfg/yolov4-tiny-custom.cfg /home/user/mask_detection/cfg/yolov4-tiny-obj.cfg |
修改內容,更改filters=24($filters=(classes + 5) * 3$)、classes=3
1 | sed -i '212s/255/24/' /home/user/mask_detection/cfg/yolov4-tiny-obj.cfg |
執行以下指令,計算 `anchors
1 | /home/user/darknet detector calc_anchors /home/user/mask_detection/cfg/mask.data -num_of_clusters 6 -width 416 -height 416 -showpause |
得到
1 | anchors = 8, 15, 16, 28, 25, 42, 38, 64, 66, 99, 136,151 |
修改 yolov4-tiny-custom.cfg 內容
1 | sed -i '219s/10,14, 23,27, 37,58, 81,82, 135,169, 344,319/8, 15, 16, 28, 25, 42, 38, 64, 66, 99, 136,151/' /home/user/mask_detection/cfg/yolov4-tiny-obj.cfg |
下載官方已經訓練好的 weights
下載 yolov4-tiny.conv.29 後放到 cfg 下
現在的目錄結構為
1 | /home/user |
訓練模型
訓練
1 | cd /home/user/darknet |
- darknet 指令格式:
darknet detector [動作] [.data] [.cfg] [weights檔] [options] - 訓練的 weights 會存在
/home/user/mask_detection/cfg/weights/ -gpus:可使用多 GPU,後面數字為 GPU 代號,執行指令nvidia-smi即可查看代號。-dont_show:過程中不要展示 loss 圖片。-map:顯示 mAP。產出的
weights1
2
3
4
5
6
7
8
9
10
11/home/user/mask_detection/cfg/weights
├─yolov4-tiny-obj_final.weights
├─yolov4-tiny-obj_last.weights
├─yolov4-tiny-obj_500000.weights
├─yolov4-tiny-obj_490000.weights
├─yolov4-tiny-obj_480000.weights
├─...
├─...
├─...
├─yolov4-tiny-obj_20000.weights
└─yolov4-tiny-obj_10000.weightsmAP vs loss
mAP vs loss
測試
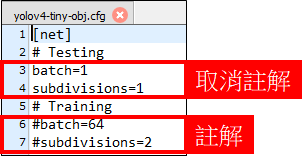
先修改
cfg檔Test configure測試圖片
1
2cd /home/user/darknet
./darknet detector test ../mask_detection/cfg/mask.data ../mask_detection/cfg/yolov4-tiny-obj.cfg ../mask_detection/cfg/weights/yolov4-tiny-obj_final.weights <filename>測試完會產出圖檔再 darknet 目錄下
/home/user/darknet/predictions.jpg測試1測試2測試影片
1
2cd /home/user/darknet
./darknet detector demo ../mask_detection/cfg/mask.data ../mask_detection/cfg/yolov4-tiny-obj.cfg ../mask_detection/cfg/weights/yolov4-tiny-obj_final.weights <video_filename> -out_filename <output_filename.avi>
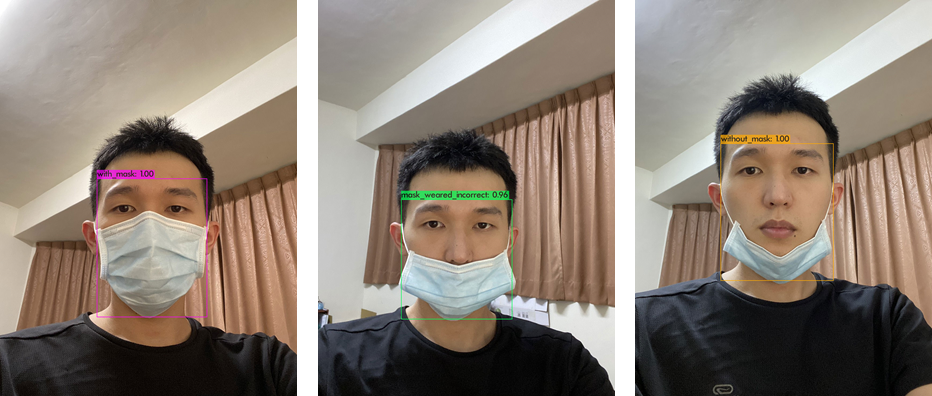

Line Bot 應用
上傳圖片給官方帳號,官方帳號會回覆經過 YOLOv4 的照片
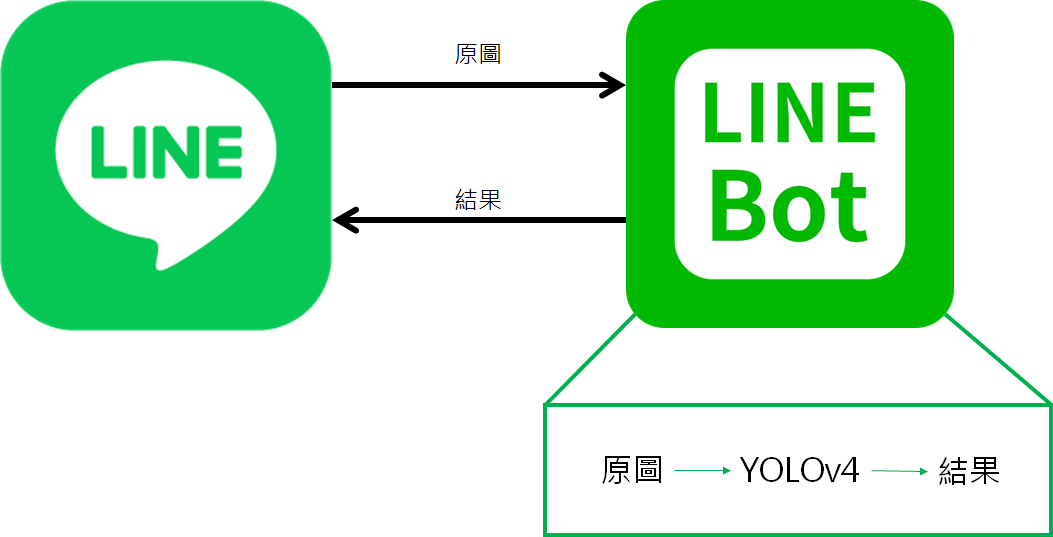 Line Bot 運作原理
Line Bot 運作原理
Demo 影片
Line Bot QR Code
 Line Bot QR Code
Line Bot QR Code
將 YOLOv4 整合在應用程式中的核心程式碼
1 | from darknet import darknet |
參考資料
問題排除
編譯 darknet 時可能遇到的問題
/bin/sh: 1: nvcc: not found
將Makefile的NVCC=nvcc改為NVCC=/usr/local/cuda-10.0/bin/nvcc,此路徑因環境而異。
訓練時可能遇到的問題
- Out of memory
嘗試更改改cfg檔案中的subdivision,YOLO 一次會讀取num(trainingData)/batch/subdivision份資料到記憶體中,因此若記憶體不夠,則調整subdivision試試!
其他問題
歡迎留言發問交流。

